RSS 进阶篇:Huginn - 真·为任意网页定制 RSS 源(PhantomJs 抓取)
在互联网信息海量增长的时代,RSS 作为一种高效的信息获取工具,能够帮助用户筛选、订阅感兴趣的内容,实现信息的快速获取和管理。相较于传统的 RSS 源创建工具,Huginn 以其高度的自定义性和灵活性脱颖而出。本教程将引导你使用 Huginn 和 PhantomJs Cloud 为任意网页定制 RSS 源,无论是静态页面还是动态加载的内容。
准备工作
在开始之前,你需要做些准备:
服务器环境:一个已安装 Debian 或 Ubuntu 的服务器,或者一个 NAS 设备。
Huginn 部署:参考 Huginn Docker 安装指南 完成 Huginn 的搭建。
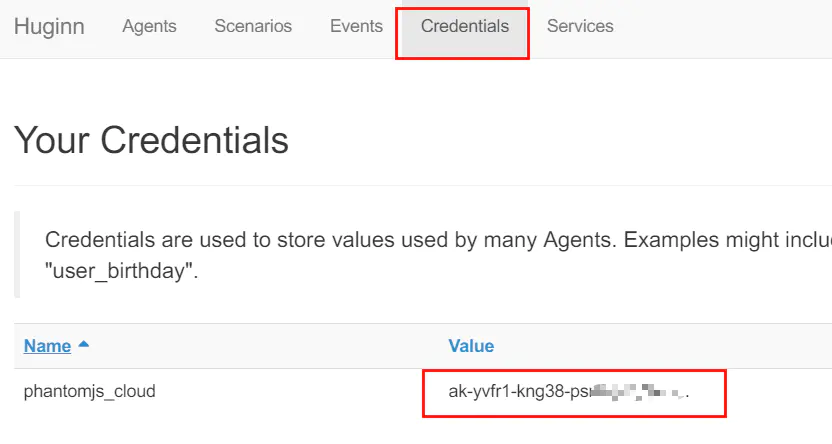
PhantomJs Cloud:访问PhantomJs Cloud注册账号,并将 API key 添加至 Huginn 的 Credentials。PhantomJs Cloud 能够抓取 JS 动态加载的内容,对于大多数个人用户的需求,其免费版的日抓取限制(500 次)已足够。也可以注册多个账号以突破限制。
Huginn 网页抓取
1. 创建任务组
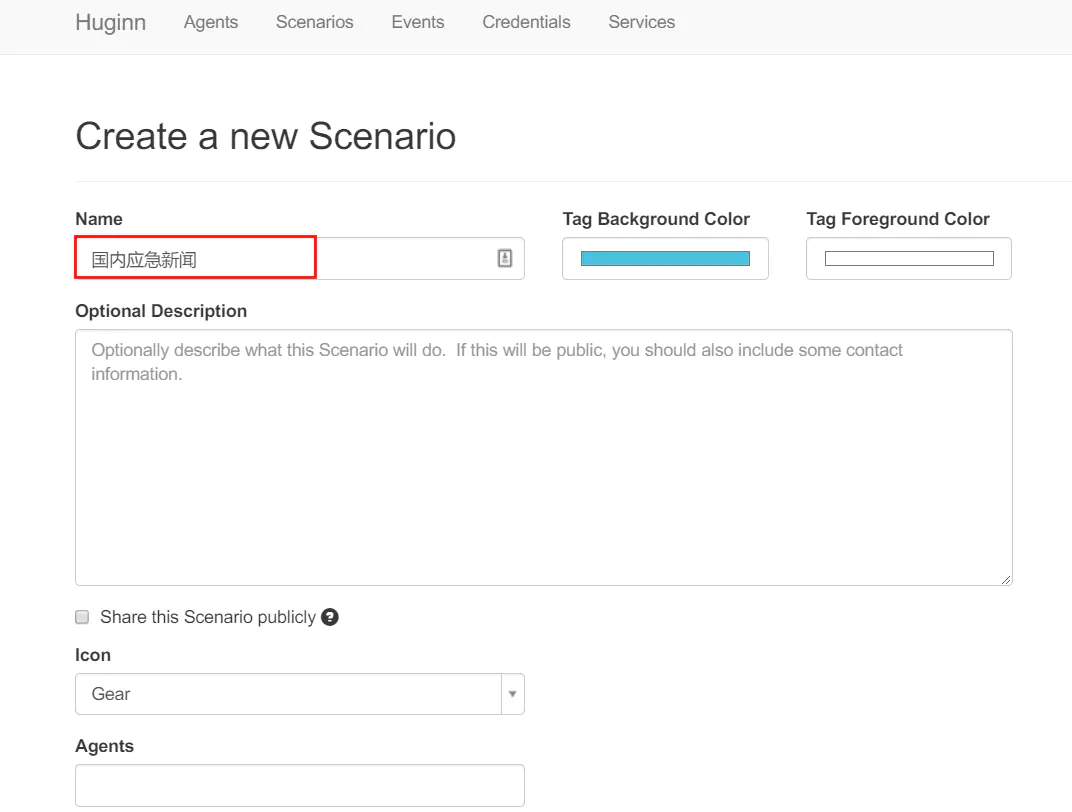
在 Huginn 中新建一个任务组 Scenario,例如命名为「国内应急新闻」,并选择合适的抓取链接,如 http://www.cneb.gov.cn/guoneinews/。
2. 使用 PhantomJs Cloud 缓存页面
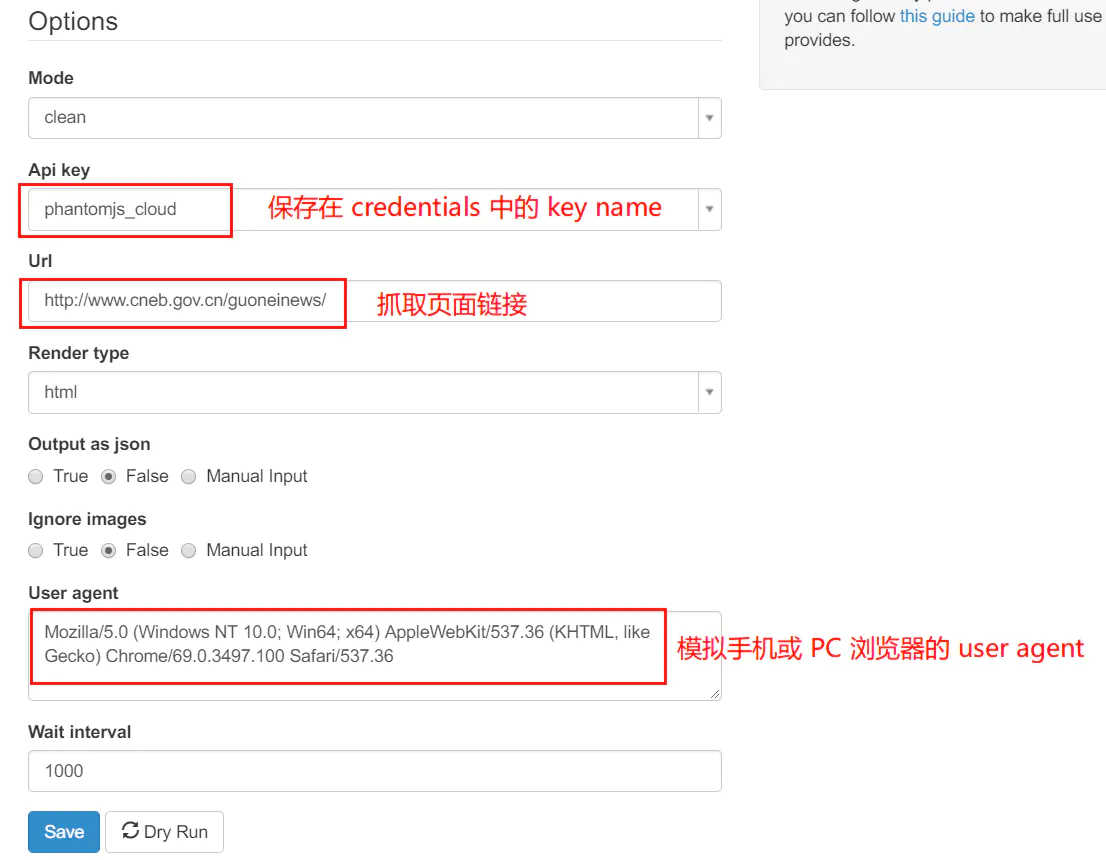
(静态页面可跳过本步)创建一个 PhantomJs Cloud Agent 任务,配置它以获取目标网页的动态内容缓存。注意,某些链接,特别是小城市的地方网站,即使是缓存后的链接也可能无法打开。这通常是由于数据通过第三方链接注入造成的。你可以利用网页浏览器工具定位到真正的数据链接再进行抓取。
3. 解析网页内容
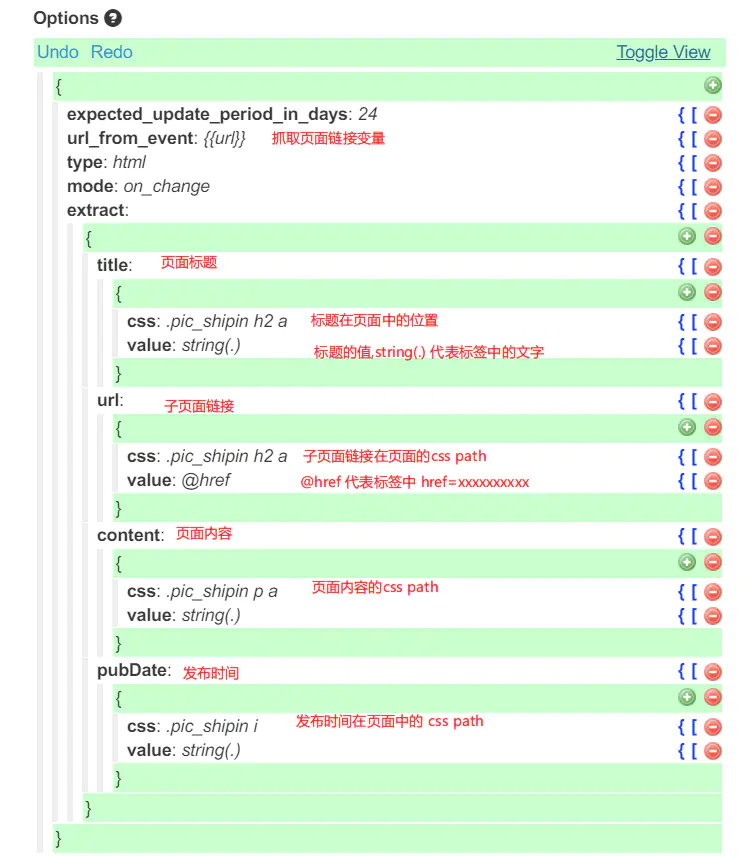
通过 WebsiteAgent 抓取网页内容。
4. 获取内容路径
通过浏览器的开发者工具来获取元素的 Xpath 或 CSS Path。请按照以下步骤操作:
打开开发者工具:
- 在浏览器中打开你想要抓取内容的网页。
- 按下
F12键或右键点击页面,选择“检查元素”(Inspect Element),以打开开发者工具。
选择要抓取的内容:
- 在开发者工具的左上角,点击检查指针图标,然后在页面上选择你想要抓取的元素。选中后,该元素的代码将在开发者工具中高亮显示。


获取路径:
- 右键点击开发者工具中高亮显示的代码部分,选择“复制”(Copy),然后根据你的需要选择
Xpath(Chrome 浏览器) 或CSS Path(Firefox 浏览器)。

- 右键点击开发者工具中高亮显示的代码部分,选择“复制”(Copy),然后根据你的需要选择
处理路径
规范 Xpath 路径
使用 Xpath 时,路径中含有的双引号需要特别处理,以避免与 JSON 配置冲突。主要有两种方法:
替换为单引号:将
Xpath路径中的双引号 (") 替换为单引号 (')。例如,原始路径为//*[@id="video-title"],处理后为//*[@id='video-title']。使用反义符转义双引号:在双引号前添加反义符 (
\) 来转义双引号。例如,原始路径为//*[@id="video-title"],处理后为//*[@id=\"video-title\"]。
简化 css path 路径
css path可能非常长。为了提高效率和准确性,你可以简化这个路径。接下来,我会以原始路径 html body div.area.areabg1 div.area-half.right div.tabBox div.tabContents.active table tbody tr td.red a 为例进行简化。
首先,删去不带
.或#的节点(节点间以空格“ ”分割),并删去每个节点在.或#前的第一个标签,得到.area.areabg1 .area-half.right .tabBox .tabContents.active .red a。更进一步简化,如果前半部分对定位目标元素不是必须的,可以省略(比如:中国上海,省略掉中国,大家也知道上海在哪),获得短路径
.tabContents.active .red a。特殊路径处理:
- 空格替换为点:当类名中包含空格时,意味着该元素同时拥有多个类。在 css path 中,这些空格应该用
.来替代,确保正确匹配。例如:<div class="packery-item article">处理后为.packery-item.article。 - 多规则选择:当需要同时匹配多个不同的 css path 时,可以使用逗号
,将它们分隔开。例如:"css": ".focus-title .current a , .stress h2 a",。
- 空格替换为点:当类名中包含空格时,意味着该元素同时拥有多个类。在 css path 中,这些空格应该用
动态页面判断
当使用上方路径抓取页面,却没返回任何结果,这可能是由于页面内容是动态生成的。
这时,可以尝试将 xpath 或 css path 修改为 html,然后尝试再次抓取。这样做可以让你获取并查看整个页面的 HTML 源码。检查源码,看是否包含你期望抓取的内容。如果源码中没有,但在浏览器中可以看到内容,这表明内容很可能是动态加载的。然后回到上方的第二步,使用 PhantomJs Cloud 来缓存页面。
导出 RSS
配置 RSS 源:使用 Data Output Agent 以指定输出内容的格式和结构。配置完成后,DataOutputAgent 将自动将抓取的数据转换为 RSS 格式源。

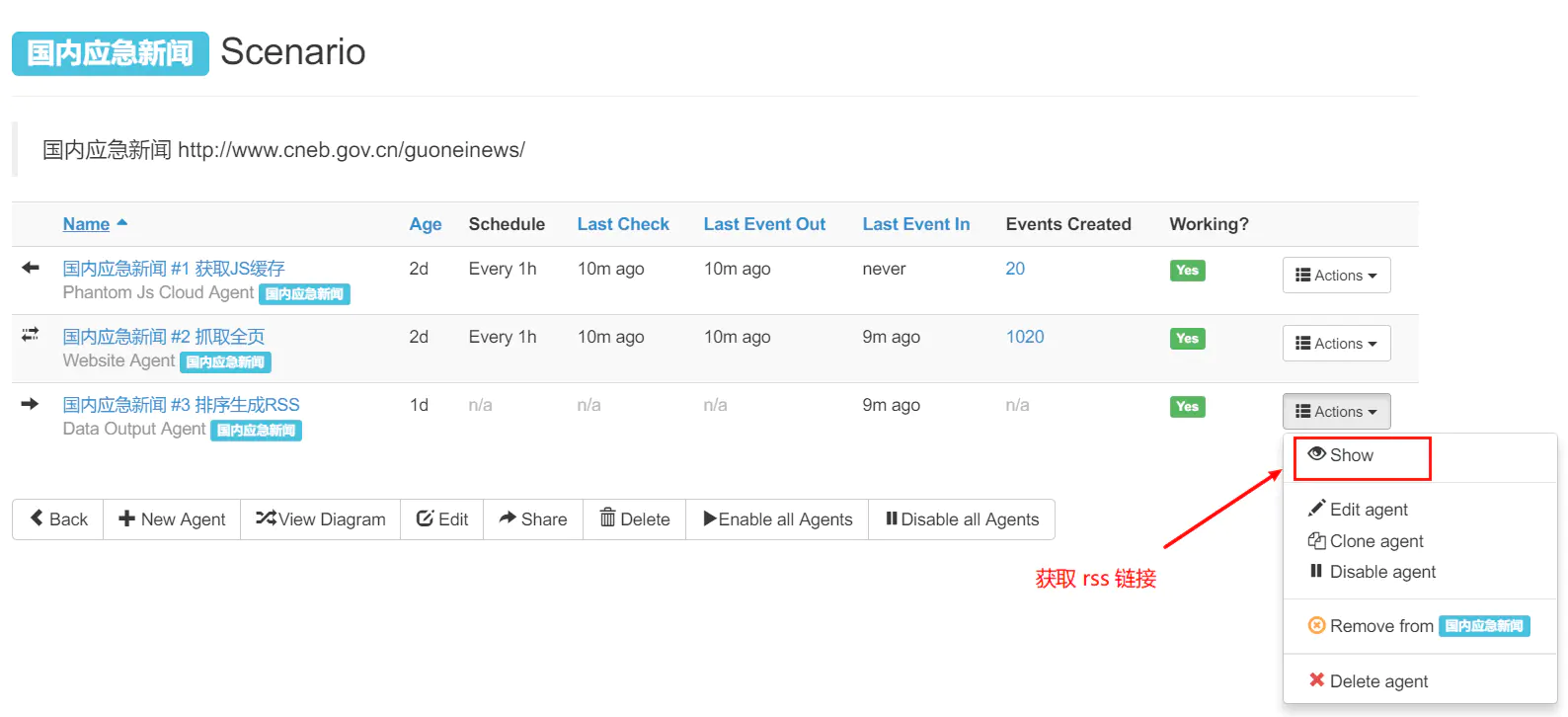
获取 RSS 链接:
- 完成配置后,回到 Scenarios 页面。
- 找到您的 Data Output Agent,并点击旁边的「Actions」>「Show」按钮。
- 您将看到一个 XML 链接,这个链接就是您个性化 RSS 源的地址。复制这个链接,您就可以在任何 RSS 阅读器中订阅这个源了。
上方的配置样例可以点击网盘下载,将其导入到 Huginn 即可使用。其他问题参考 PhantomJs Cloud 英文攻略。
跳转链接处理示例
要获取跳转链接的真实地址,可以使用 WebsiteAgent 直接读取原网页的 HTML 代码,并检查其中的跳转代码。
跳转代码通常位于<script>标签内。由于<script>标签内的内容是文本,而非 HTML 属性,我们不能使用属性选择器(如@href)。相反,我们应使用 XPath 的string()函数来提取整个<script>标签的文本内容。之后,可以利用 EventFormattingAgent 的正则表达式从这些文本中提取 URL。
# WebsiteAgent
{
"expected_update_period_in_days": "2",
"url": "https://www.chncpa.org/ycxm/202308/t20230817_254985.html",
"type": "html",
"mode": "on_change",
"extract": {
"url": {
"xpath": "//script",
"value": "string(.)"
}
}
}
# EventFormattingAgent
{
"instructions": {
"jumpurl": "{{real_url.1}}"
},
"matchers": [
{
"path": "{{url}}",
"regexp": "window\\.location\\.href\\s*=\\s*\\\\?[\"']([^\"']+?)(?:\\\\?[\"']);",
"to": "real_url"
}
],
"mode": "clean"
}RSS 合集
汇总的 RSS 永久订阅 feeds,均通过 RSSHub 和 Huginn 制作。微信的屏蔽措施非常之多,公众号抓取可以尝试搜狗搜索来获取。如果有兴趣自制 RSS,可参考以下教程。